Строим Data Pipeline на Python и Luigi

Введение
В эпоху data-intensive приложений рядовым разработчикам всё чаще приходится сталкиваться с задачами по обработке и анализу данных. Ещё десять лет назад данные большинства проектов могли уместиться на жестком диске одного компьютера в какой-нибудь реляционной базе данных типа MySQL. А задачи по извлечению и обработке хранящихся данных решались за счёт непростых (или простых) SQL запросов. С тех пор мир информационных технологий значительно поменялся. С приходом Internet of Things, мобильных телефонов и дешевого мобильного интернета, объем генерируемых данных вырос в десятки тысяч раз. Ежедневно в мире генерируются эксабайты данных. Анализировать такой поток информации вручную, а тем более извлекать полезные для бизнеса или науки данные, практически невозможно. Но технологии как и время не стоят на месте, появляются новые инструменты, наука двигает прогресс. Если вы хоть чуточку следите за новостями из мира высоких технологий, то фразы "биг дата", "машинное обучение", "глубокое обучение" вас не испугают. С приходом больших данных появились новые профессии и специализации такие как Data Scientist/Analyst (по-русски аналитик данных), Data Engineer. Задачи этих ребят тесно связаны с обработкой, анализом и хранением "нефти 21 века", т.е. информации. Но насколько эффективно они выполняются?
ETL
Аббревиатура ETL в последнее время часто мелькает в материалах, посвященных data-driven приложениям. Но не пугайтесь, это всего лишь набор из 3-х простых слов: Extract, Transform, Load. Ничего не напоминает? Тот, кто сталкивался с задачами по обработке данных не раз замечал паттерн в своих действиях, а именно:
сначала данные выгружаются (Extract) из какого-нибудь источника типа базы данных, внешнего сервиса (Facebook Ads, Google Analytics, Yandex Metrics) или, на худой конец, это могут быть логи вашего приложения (например, веб-сервера).
потом они преобразуются (Transform), скажем, необходимо сформировать сводную таблицу или провести сложный когортный анализ ваших пользователей.
и наконец загружаются (Load) для просмотра и дальнейшего анализа в базу данных или на какое-нибудь облако Amazon S3, не суть.
И как ни крути от этого не уйти. Чтобы данные проанализировать, их необходимо подготовить, иначе "мусор на входе — мусор на выходе". Процесс подготовки занимает львиную долю времени, отведенного на работу с данными. До 80% рабочего времени аналитик тратит на сбор и очистку. Поэтому от эффективности ETL-процесса зависит скорость и качество выполненной работы.
Перед тем как перейти к основной идеи этой статьи, я предлагаю кратко рассмотреть самый популярный на сегодняшний день метод построения ETL процесса в компании.
Серые будни работы с данными
Сложно спорить с утверждением, что Python твердо занял позицию lingua franca в задачах по анализу данных. О его взрывной популярности свидетельствует и недавний пост от ребят из Stack Overflow. Но что же предшествует магическому процессу извлечения ценной информации (непосредственному анализу) из гигабайт структурированных и неструктурированных данных? Сбор. Задачи по анализу данных славятся своими жесткими сроками ведь на их основе часто принимают ключевые бизнес-решения. Это сильно отражается на том как мы, разработчики, подходим к процессу написания скриптов. Нам не стыдно создавать скрипты-однодневки с хрупким кодом и горой "разбитых окон". Хорошо ещё, если в этой массе кода есть хоть какая-нибудь структура или модульность для дальнейшего переиспользования в других скриптах, но обычно и этого нет. Краткосрочный выигрыш в скорости оборачивается головными болями в долгосрочной перспективе. Код обрастает "техническим долгом", и им становится сложно управлять. Ниже пример ETL-скрипта с соблюдением принципа Single Responsibility в каждой функции:
def extract_important_data():
pass
def clean_important_data():
pass
def transform_important_data():
pass
def join_important_data_with_another_important_data():
pass
def load_to_db():
pass
if __name__ == "__main__":
extract_important_data()
clean_important_data()
transform_important_data()
join_important_data_with_another_important_data()
load_to_db()
Всё бы хорошо, но у такого подхода есть ряд проблем:
- отсутствие хорошего и централизованного обработчика ошибок
- проблема при управлении зависимостями (между функциями/классами)
- восстановление в точке остановки скрипта вследствии ошибки (например, получили 500 ошибку от одного из API сервисов)
- удобная и быстрая работа с командной строкой (при необходимости передавать в скрипт аргументы)
Все они решаемы, но нужно ли изобретать ещё один, когда он давно изобретен и на нём успешно "катаются" специалисты в индустрии?!
Luigi
Luigi это один из немногих инструментов в экосистеме Python для построения т.н. pipeline’ов или, по-простому, выполнения пакетных задач (batch jobs). Разработан был инженерами из Spotify. Мне он понравился за свою простоту и широкий спектр возможностей, а именно:
управление зависимостями между задачами
failover recovery, т.е. если в одной из задач произошла ошибка, не нужно перезапускать цепочку снова
центральный планировщик задач с веб-интерфейсом, статусом выполнения задач и трекингом ошибок
“батарейки” для работы с HDFS, S3, MySQL, PostgreSQL, Redis, MongoDB, Redshift и т.д.
удобное построение CLI (Command Line Interface), в нём очень удобно построена передача параметров из командной строки
Основными строительными блоками Luigi являются 3 объекта: Task, Target и Parameter. Последний используется для взаимодействия с командной строкой и поэтому опционален. Чтобы установить Luigi достаточно выполнить:
pip install luigiTask
Класс Task это основной блок, где происходит выполнение конкретного таска. Чтобы определить свою собственную задачу, необходимо создать класс, унаследованный от Task, и реализовать несколько методов. Зачастую переопределять нужно только 3 метода: run(), output(), requires().
На сайте с документацией к Luigi есть хорошая иллюстрация что из себя представляет каждый метод и класс в целом:
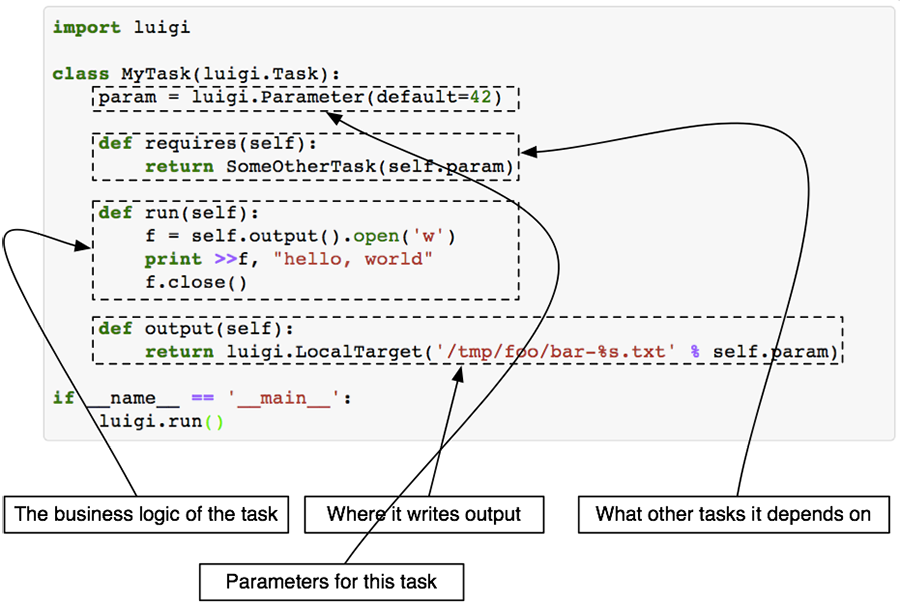
Task.run
Здесь выполняется вся логика вашей будущей задачи, например, скачивание или парсинг данных с внешнего источника, запрос в базу данных для извлечения информации и т.д. Если задача объёмная, то лучше разбить её на функции и вызывать их внутри метода run(), это поможет избежать путанницы в будущем.
Task.requires
Помните я говорил об управлении зависимостями? В методе requires() необходимо их перечислить. Зависимостями выступают другие luigi.Task классы. Чуть позже я покажу реальный пример задачи с зависимостями.
Task.output
Этот метод должен возвращать 1 или более Target объектов. Target объектом может быть файл на диске, файл внутри HDFS, S3 или файл, лежащий на удалённом FTP сервере и т.д.. В Luigi уже встроено множество полезных Target классов, поэтому ситуация, когда вам понадобится создавать свой, маловероятна. Полный список доступных Target классов смотрите на сайте.
Task.input
Этот метод не нужно переопределять. Он выступает "оберткой" над Task.requires и возвращает Target объекты, полученные от выполнения задач, определенных в Task.requires. Таким образом строится граф зависимостей, когда одна задача зависит от результата выполнения другой. Продемонстрирую на примере кода:
import luigi
class A(luigi.Task):
def output(self):
return luigi.LocalTarget('result.txt')
def run(self):
with self.output().open('w') as f:
f.write('Hello, Luigi!')
class B(luigi.Task):
def requires(self):
return A()
def run(self):
with self.input().open('r') as f:
print(f.read())
if __name__ == '__main__':
luigi.run()
Здесь таск B зависит от выполнения таска A, поэтому перед началом выполнения B выполнится A, результат которого вернётся при вызове метода B.input (объекта файла result.txt).
Target
Ранее я вкратце описал что из себя представляет объект Target и зачем он нужен. Здесь отмечу, что благодаря этому классу Luigi реализует механизм fault tolerance и свойство идемпотентности. Проще говоря, если ваш pipeline аварийно завершается где-то в середине выполнения задач, повторный запуск не приведёт к повторному запуску успешно завершившихся задач, выполнение начнется в месте аварийной остановки скрипта. Это достигается за счёт вызова метода exists() у Target класса.
Parameter
При создании ETL скриптов часто приходится писать код для работы с командной строкой, а именно уметь принимать и обрабатывать аргументы. Даже наличие в стандартной библиотеке Python модулей для работы с консолью не уменьшает количество boilerplate кода. Luigi решил эту проблему по-своему.
Чтобы принимать аргументы из командной строки достаточно присвоить переменной объект класса Parameter или его наследников на уровне класса.
class TaskA(luigi.Task):
filename = luigi.Parameter()
def output(self):
return luigi.LocalTarget('{}.txt'.format(self.filename))
def run(self):
with self.output().open('w') as f:
f.write('Hello, Luigi!')
Пример запуска такого скрипта:
python demo.py TaskA --filename helloworld --local-schedulerЕсли в названии вашего параметра присутствует знак ‘_’, то в командной строке его необходимо заменить на ‘-’. То есть передача значения в переменную file_name из командной строки будет выглядеть как --file-name. Параметр --local-scheduler необходим для запуска Luigi без центрального планировщика, в режиме тестирования и разработки.
Luigid
Задача демона Luigi заключается в следующем:
Следить за выполнением задач, чтобы исключить ситуацию одновременного исполнения одного и того же таска
Визуализация работы скрипта: построение графа зависимостей, просмотр статусов у текущих задач, мониторинг ошибок
Ниже скриншот графа зависимостей внутри демона Luigi на примере простого скрипта о котором расскажу чуть ниже.
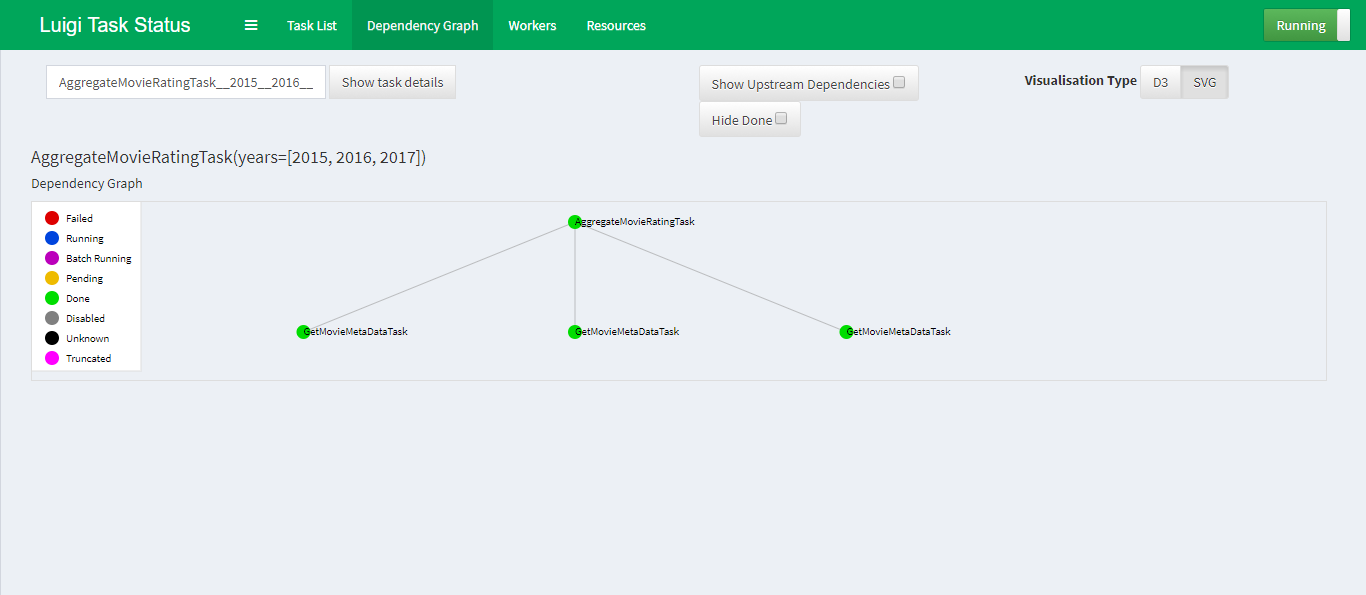
По умолчанию демон слушает 8082 порт и запускается командой:
luigidЧтобы увидеть все доступные параметры запуска необходимо добавить --help.
Пример пайплайна
Человек лучше всего запоминает информацию на практических примерах, поэтому я придумал скрипт в задачу которого входит:
- спарсить рейтинг фильмов по годам с сайта IMDB
- сохранить результат каждого года в файл
- объединить результаты всех лет в 1 файл и отсортировать фильмы по убыванию рейтинга и количества голосов
Вот как выглядит решение этой задачи в Luigi:
import csv
import luigi
from luigi.format import UTF8
import requests
import pandas as pd
from bs4 import BeautifulSoup
class AggregateMovieRatingTask(luigi.Task):
years = luigi.ListParameter()
def requires(self):
return [GetMovieMetaDataTask(year) for year in self.years]
def output(self):
return luigi.LocalTarget('results.csv'.format(), format=UTF8)
def run(self):
data_frames = []
for _input in self.input():
with _input.open('r') as raw_file:
data_frames.append(pd.read_csv(raw_file))
df = pd.concat(data_frames)
df = df.sort_values(['rating', 'votes'], ascending=[False, False])
with self.output().open('w') as f:
df[['title', 'rating', 'votes']].to_csv(f)
class GetMovieMetaDataTask(luigi.Task):
year = luigi.Parameter()
def get_movie_meta_data(self, film_div):
title = film_div.h3.a.text
rating = film_div.find('div', class_='ratings-imdb-rating')
rating = rating.attrs['data-value'] if rating else 0
votes = film_div.find('span', attrs={'name': 'nv'})
votes = votes.attrs['data-value'] if votes else 0
return {'title': title, 'rating': rating, 'votes': votes}
def output(self):
return luigi.LocalTarget('raw-{}.csv'.format(self.year), format=UTF8)
def run(self):
url = 'http://www.imdb.com/search/title?release_date={}'.format(self.year)
response = requests.get(url, headers={
'Accept-Language': 'ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4'
})
response.raise_for_status()
html = BeautifulSoup(response.text, 'html.parser')
film_container = html.find_all('div', class_='lister-item mode-advanced')
payload = [self.get_movie_meta_data(film) for film in film_container]
with self.output().open('w') as csv_file:
df = pd.DataFrame(payload)
df.to_csv(csv_file)
if __name__ == '__main__':
luigi.run()
Скачать скрипт можно по ссылке. Для корректной работы необходимо помимо luigi также установить requests, pandas и beautifulsoup4:
pip install requests, pandas, beautifulsoup4, luigiЗапускайте в терминале демон luigid, а сам скрипт вот таким образом:
python imdb_luigi_list_params.py AggregateMovieRatingTask --years [2013,2014,2015,2016,2017]Отправной точкой будет класс AggregateMovieRatingTask которому передается список интересующих нас лет. В методе requires() определяется зависимость от GetMovieMetaDataTask, поэтому до тех пор пока не будет получен результат от GetMovieMetaDataTask, код в методе run() у класса AggregateMovieRatingTask не будет исполнен.
При удачном раскладе AggregateMovieRatingTask.input вернёт список, содержащий объекты LocalTarget, полученные от выполнения GetMovieMetaDataTaskпо каждому году. Дальше необходимо пробежаться по списку, сформировать DataFrame и отсортировать его по убыванию.
Полученных знаний достаточнот для построения сложных пайплайнов с зависимостями.
Ограничения Luigi
Как и у любого другого инструмента, у Luigi есть свои ограничения с которыми приходится мириться в зависимости от ситуаций.
Отсутствие механизма запуска задач по расписанию. Если такая потребность имеется, то можно использовать crontab.
Luigi не предназначен для real-time обработки, его стихия это batch processing.
Сложность масштабирования. Luigi не умеет распределять задачи между воркерами на разных узлах/нодах как это умеет делать Celery, используя единый брокер сообщений (например, Redis или RabbitMQ). Без серьёзного ручного вмешательства тут не обойтись.
Заключение
Моей главной задачей в статье было рассказать про основные возможности Luigi. Вероятно те из вас, кто до сих пор мучается с boilerplate кодом при написании ETL скриптов взглянут на свою работу иначе, и полученная информация сделает вашу работу эффективной и приятной. За более подробным описанием стоит сходить на сайт с документацией. Отмечу, что Luigi не единственный инструмент в своём роде, обратите внимание на продукт под названием Airflow, разработанный в стенах Airbnb и с недавних пор перешедший в "руки" Apache Foundation (на момент написания статьи проект находится в статусе "incubating").