 English
EnglishВведение в Apache Airflow
Также по теме Airflow:
Apache Airflow — это продвинутый workflow менеджер и незаменимый инструмент в арсенале современного дата инженера. Если смотреть открытые вакансии на позицию data engineer, то нередко встретишь опыт работы с Airflow как одно из требований к позиции.
Я разработал практический курс по Apache Airflow 2.0, он доступен на платформе StartDataJourney, создана она также мною. Приятного обучения - Apache Airflow 2.0: практический курс.
Airflow был разработан в 2014 году в компании Airbnb, автор Maxime Beauchemin. Позже инструмент был передан под опеку в организацию Apache, а в январе 2019 получил статус Top-Level проекта. В этой статье я расскажу про установку, настройку и запуск первого дата пайплайна средствами Apache Airflow. К слову, в 2017 году я уже писал про не менее классный и простой инструмент Luigi от компании Spotify. По своей сути эти два инструмента похожи — оба предназначены для запуска цепочек задач (дата пайплайнов), но есть у них и ряд различий о которых я говорил во время своего выступления на PyCON Russia 2019:
В этой статье я постараюсь рассказать о необходимом минимуме для работы с Airflow. Для начала давайте рассмотрим основные сущности инструмента.
DAG (Directed Acyclic Graph)
DAG — это ориентированный ациклический граф, т.е. граф у которого отсутствуют циклы, но могут быть параллельные пути, выходящие из одного и того же узла. Простыми словами DAG это сущность, объединяющая ваши задачи в единый data pipeline (или цепочку задач), где явно видны зависимости между узлами.
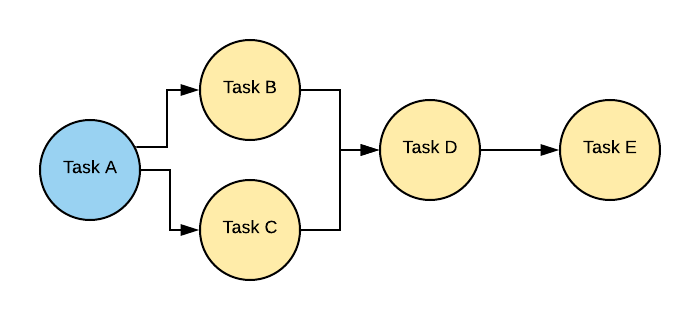
На картинке можно видеть классический DAG, где Task E является конечным в цепочке и зависит от всех задача слева от него.
Operator
Если вы знакомы с инструментом Luigi, то Operator в Airflow это аналог Task в Luigi. Оператор это звено в цепочке задач. Используя оператор разработчик описывает какую задачу необходимо выполнить. В Airflow есть ряд готовых операторов, например:
- PythonOperator — оператор для исполнения python кода
- BashOperator — оператор для запуска bash скриптов/команд
- PostgresOperator — оператор для вызова SQL запросов в PostgreSQL БД
- RedshiftToS3Transfer — оператор для запуска UNLOAD команды из Redshift в S3
- EmailOperator — оператор для отправки электронных писем
Полный список стандартных операторов можно найти в документации Apache Airflow.
DAG является объединяющей сущностью для набора операторов, т.е. если вернуться к картинке выше, то Task A, Task B и т.д. это отдельные операторы.
Важно! Операторы не могут принимать возвращаемые значения от выполнения предыдущих операторов в цепочке (как, например, цепочка из вызовов функций), т.к. могут исполняться в разном адресном пространстве и даже на разных физических машинах.
Sensor
Сенсор это разновидность Operator, его удобно использовать при реализации событийно ориентированных пайплайнов. Из стандартного набора есть, например:
- PythonSensor — ждём, когда функция вернёт
True - S3Sensor — проверяет наличие объекта по ключу в S3-бакете
- RedisPubSubSensor — проверяет наличие сообщения в pub-sub очереди
- RedisKeySensor — проверяет существует ли переданный ключ в Redis хранилище
Это лишь малая часть доступных для использования сенсоров. Чтобы создать свой сенсор, достаточно унаследоваться от BaseSensorOperator и переопределить метод poke.
Hook
Хуки это внешние интерфейсы для работы с различными сервисами: базы данных, внешние API ресурсы, распределенные хранилища типа S3, redis, memcached и т.д. Хуки являются строительными блоками операторов и берут на себя всю логику по взаимодействию с хранилищем конфигов и доступов (о нём ниже). Используя хуки можно забыть про головную боль с хранением секретной информации в коде (пароли к доступам, например).
Установка
Apache Airflow состоит из нескольких частей:
- Веб-приложение с панелью управления, написано на Flask
- Планировщик (Scheduler), в production среде чаще всего используется Celery
- Воркер, выполняющий работу. В production среде также чаще всего встречается конфигурация с Celery.
В качестве базы данных рекомендуется использовать PostgreSQL или MySQL. В этом посте речь пойдёт про установку и настройку Apache Airflow руками, я не буду использовать готовые образы Docker, чтобы наглядно показать как всё запускается изнутри.
Погнали! Создаём новое виртуальное окружение Python, и ставим в него Apache Airflow:
$ python3 -m venv .venv
$ source .venv/bin/activate
$ pip install apache-airflow
У Airflow много зависимостей в отличие от Luigi, поэтому на экране будет много текста. Вот, например, результат вывода pip freeze:
alembic==1.4.0
apache-airflow==1.10.9
apispec==1.3.3
argcomplete==1.11.1
attrs==19.3.0
Babel==2.8.0
cached-property==1.5.1
cattrs==0.9.0
certifi==2019.11.28
chardet==3.0.4
Click==7.0
colorama==0.4.3
colorlog==4.0.2
configparser==3.5.3
croniter==0.3.31
defusedxml==0.6.0
dill==0.3.1.1
docutils==0.16
Flask==1.1.1
Flask-Admin==1.5.4
Flask-AppBuilder==2.2.2
Flask-Babel==0.12.2
Flask-Caching==1.3.3
Flask-JWT-Extended==3.24.1
Flask-Login==0.4.1
Flask-OpenID==1.2.5
Flask-SQLAlchemy==2.4.1
flask-swagger==0.2.13
Flask-WTF==0.14.3
funcsigs==1.0.2
future==0.16.0
graphviz==0.13.2
gunicorn==19.10.0
idna==2.8
importlib-metadata==1.5.0
iso8601==0.1.12
itsdangerous==1.1.0
Jinja2==2.10.3
json-merge-patch==0.2
jsonschema==3.2.0
lazy-object-proxy==1.4.3
lockfile==0.12.2
Mako==1.1.1
Markdown==2.6.11
MarkupSafe==1.1.1
marshmallow==2.19.5
marshmallow-enum==1.5.1
marshmallow-sqlalchemy==0.22.2
numpy==1.18.1
pandas==0.25.3
pendulum==1.4.4
pkg-resources==0.0.0
prison==0.1.2
psutil==5.6.7
Pygments==2.5.2
PyJWT==1.7.1
pyrsistent==0.15.7
python-daemon==2.1.2
python-dateutil==2.8.1
python-editor==1.0.4
python3-openid==3.1.0
pytz==2019.3
pytzdata==2019.3
PyYAML==5.3
requests==2.22.0
setproctitle==1.1.10
six==1.14.0
SQLAlchemy==1.3.13
SQLAlchemy-JSONField==0.9.0
SQLAlchemy-Utils==0.36.1
tabulate==0.8.6
tenacity==4.12.0
termcolor==1.1.0
text-unidecode==1.2
thrift==0.13.0
typing==3.7.4.1
typing-extensions==3.7.4.1
tzlocal==1.5.1
unicodecsv==0.14.1
urllib3==1.25.8
Werkzeug==0.16.1
WTForms==2.2.1
zipp==2.2.0
zope.deprecation==4.4.0
После установки пакета apache-airflow, в виртуальном окружении будет доступна команда airflow. Запустите её без параметров, чтобы увидеть список доступных команд.
Apache Airflow свои настройки хранит в файле airflow.cfg, который по умолчанию будет создан в домашней директории юзера по пути ~/airflow/airflow.cfg. Путь можно изменить, присвоив переменной окружения новое значение:
$ export AIRFLOW_HOME=~/airflow/
Далее выполняем инициализацию для базы данных.
$ airflow initdb
Эта команда накатит все миграции, по умолчанию в качестве базы данных Airflow использует SQLite. Для демонстрационных возможностей это нормально, но в реальном бою лучше всё же переключиться на MySQL или PostgreSQL. Давайте делать всё по-взрослому. Я буду использовать Postgres, поэтому если он у вас до сих пор не стоит, то самое время установить PostgreSQL.
Создаю базу данных и пользователя к ней для Airflow:
postgres=# create database airflow_metadata;
CREATE DATABASE
postgres=# CREATE USER airflow WITH password 'airflow';
CREATE ROLE
postgres=# grant all privileges on database airflow_metadata to airflow;
GRANT
А теперь открываем airflow.cfg и правим значение параметра sql_alchemy_conn на postgresql+psycopg2://airflow:airflow@localhost/airflow_metadata и load_examples = False. Последний параметр отвечает за загрузку примеров с бесполезными DAGами, они нам не нужны.
В качестве python-драйвера для PostgreSQL я использую psycopg2, поэтому её необходимо поставить в окружение:
$ pip install psycopg2==2.8.4
Инициализируем новую базу данных:
$ airflow initdb
Airflow Executors
Хочу немножко отвлечься от запуска Airflow и рассказать про очень важную концепцию — Executors. Как понятно из названия, Executors отвечают за исполнение задач. В Airflow есть несколько видов исполнителей:
- SequentialExecutor
- LocalExecutor
- CeleryExecutor
- DaskExecutor
- KubernetesExecutor
В боевой среде чаще всего встречается CeleryExecutor, который, как можно догадаться, использует Celery. Но обо всём по порядку.
SequentialExecutor
Этот исполнитель установлен в качестве значения по умолчанию в airflow.cfg у параметра executor и представляет из себя простой вид воркера, который не умеет запускать параллельные задачи. Как можно догадаться, в конкретный момент времени выполняться может только одна единственная задача. Этот вид исполнителя используют в ознакомительных целях, для продуктивной среды он категорически не подходит.
LocalExecutor
Этот вид исполнителя даёт максимальные ощущения продуктивной среды в тестовом окружении (или окружении разработки). Он умеет выполнять задачи параллельно (например, исполнять несколько DAGов одновременно) путём порождения дочерних процессов, но всё же не совсем предназначен для продакшена ввиду ряда проблем:
- Ограничение при масштабировании (возможно эта проблема не будет актуальна для вас), исполнитель этого типа ограничен ресурсами машины на котором он запущен
- Отсутствие отказоустойчивости. Если машина с этим типом воркера падает, то задачи перестают исполнять до момента её возвращения в строй.
При небольшом количестве задач всё же можно использовать LocalExecutor, т.к. это проще, быстрее и не требует настройки дополнительных сервисов.
CeleryExecutor
Наиболее популярный вид исполнения задач. Под капотом использует всю магию таск-менеджера Celery, а соответственно тянет за собой все зависимости этого инструмента. Чтобы использовать CeleryExecutor необходимо дополнительно настроить брокер сообщений. Чаще всего используют либо Redis либо RabbitMQ. Преимущества этого вида в том, что его легко масштабировать — поднял новую машину с воркером, и он готов выполнять требуемую работу, а также в отказоустойчивости. В случае падения одного из воркеров его работа будет передана любому из живых.
DaskExecutor
Очень похож на CeleryExecutor, но только вместо Celery использует инструмент Dask, в частности dask-distributed.
KubernetesExecutor
Относительно новый вид исполнения задач на кластере Kubernetes. Задачи исполняются как новые pod инстансы. В связи с развитием контейнеров и их повсеместным использованием, данный вид исполнения может быть интересен широкому кругу людей. Но у него есть минус — если у вас нет Kubernetes кластера, то настроить его будет непростым упражнением.
Так к чему я начал разговор про Executors. В стандартной конфигурации Airflow предлагает нам использовать SequentialExecutor, но мы ведь стараемся подражать продуктивной среде, поэтому будем использовать LocalExecutor. В airflow.cfg поменяйте значение параметра executor на LocalExecutor.
Запускаем веб-приложение на 8080 порту:
$ airflow webserver -p 8080
Если всё настроено правильно, то переход по адресу localhost:8080 должен показать страницу как на скриншоте:
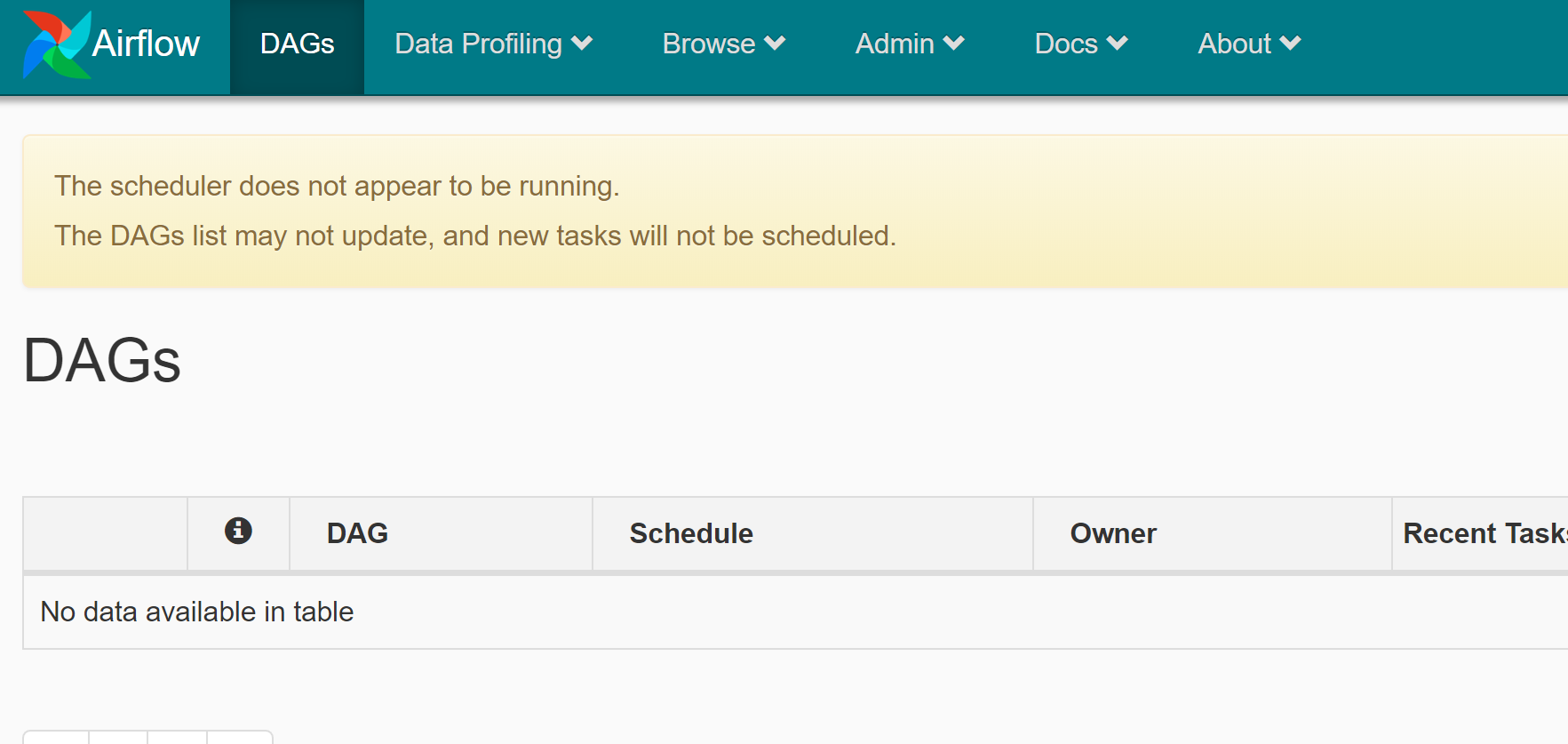
Поздравляю! Мы настроили и запустили Apache Airflow. На странице можно заметить сообщение:
The scheduler does not appear to be running. The DAGs list may not update, and new tasks will not be scheduled.
Сообщение указывает на то, что не запущен планировщик Airflow (scheduler). Он отвечает за DAG discovery (обнаружение новых DAG), а также за планирование их запуска. Запустить планировщик можно командой:
$ airflow scheduler
Для того, чтобы не переключаться между разными окнами терминалов, я люблю использовать менеджер терминалов tmux.
Итак, база настроена, веб-приложение и планировщик запущены. Нам остаётся только написать наш первый data pipeline и почувствовать себя в шкуре крутого дата инженера.
Строим data pipeline на Apache Airflow
В файле настроек airflow.cfg есть параметр dags_folder, он указывает на путь, где лежат файлы с DAGами. Это путь $AIRFLOW_HOME/dags. Именно туда мы положим наш код с задачами.
Какие задачи будет выполнять пайплайн? Я решил для демонстрации взять пример с датасетом Titanic о котором писал в статье про pandas. Суть в том, что сначала необходимо будет скачать датасет, следующим шагом будет этап создания сводной таблицы: сгруппируем пассажиров по полу и пассажирскому классу, чтобы узнать количество людей в каждом классе. Результатом будет новый csv-файл со сводной таблицей.
Вот так выглядит DAG:
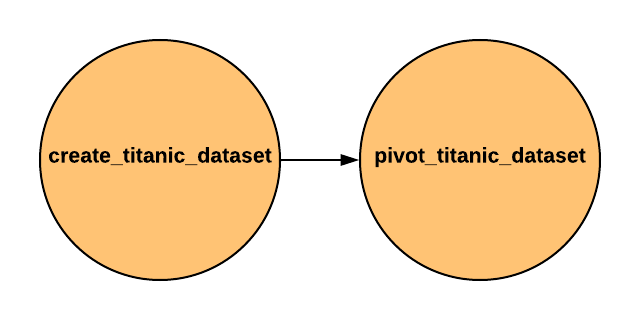
А вот код всего DAGа, включая 2 оператора:
import os
import datetime as dt
import requests
import pandas as pd
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
args = {
'owner': 'airflow',
'start_date': dt.datetime(2020, 2, 11),
'retries': 1,
'retry_delay': dt.timedelta(minutes=1),
'depends_on_past': False,
}
FILENAME = os.path.join(os.path.expanduser('~'), 'titanic.csv')
def download_titanic_dataset():
url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv'
response = requests.get(url, stream=True)
response.raise_for_status()
with open(FILENAME, 'w', encoding='utf-8') as f:
for chunk in response.iter_lines():
f.write('{}\\n'.format(chunk.decode('utf-8')))
def pivot_dataset():
titanic_df = pd.read_csv(FILENAME)
pvt = titanic_df.pivot_table(
index=['Sex'], columns=['Pclass'], values='Name', aggfunc='count'
)
df = pvt.reset_index()
df.to_csv(os.path.join(os.path.expanduser('~'), 'titanic_pivot.csv'))
with DAG(dag_id='titanic_pivot', default_args=args, schedule_interval=None) as dag:
create_titanic_dataset = PythonOperator(
task_id='download_titanic_dataset',
python_callable=download_titanic_dataset,
dag=dag
)
pivot_titanic_dataset = PythonOperator(
task_id='pivot_dataset',
python_callable=pivot_dataset,
dag=dag
)
create_titanic_dataset >> pivot_titanic_dataset
В DAGе у нас используются 2 PythonOperator. Обратите внимание, что они принимают функцию, которую необходимы выполнить. В первом случае это download_titanic_dataset, которая скачивает датасет из сети, во втором случае это pivot_dataset, которая сохраняет сводную таблицу из исходного файла (сохраненного предыдущей функцией).
Стоит обратить внимание на объект DAG и то как описаны зависимости между двумя операторами. В Airflow допустимы конструкции >> и <<, а также методы .set_upstream и .set_downstream. Т.е. код:
create_titanic_dataset >> pivot_titanic_datasetМожно заменить на:
pivot_titanic_dataset.set_upstream(create_titanic_dataset)
# или
pivot_titanic_dataset << create_titanic_datasetЭто означает, что выполнение оператора pivot_titanic_dataset зависит от выполнения оператора create_titanic_dataset.
На уровне объекта DAG задаются настройки, например:
- Время начала выполнения пайплайна (
start_date) - Периодичность запуска (
schedule_interval) - Информация о владельце DAG (
owner) - Количество повторений в случае неудач (
retries) - Пауза между повторами (
retry_delay)
Параметров в разы больше. Более подробно как всегда можно прочитать в доках.
Итак, сохраняем в файл код и помещаем его по пути $AIRFLOW_HOME/dags. Для того, чтобы DAGи отображались в интерфейсе Airflow необходимо запустить планировщик:
$ airflow schedulerЕсли всё сделано верно, то в списке появится наш DAG:
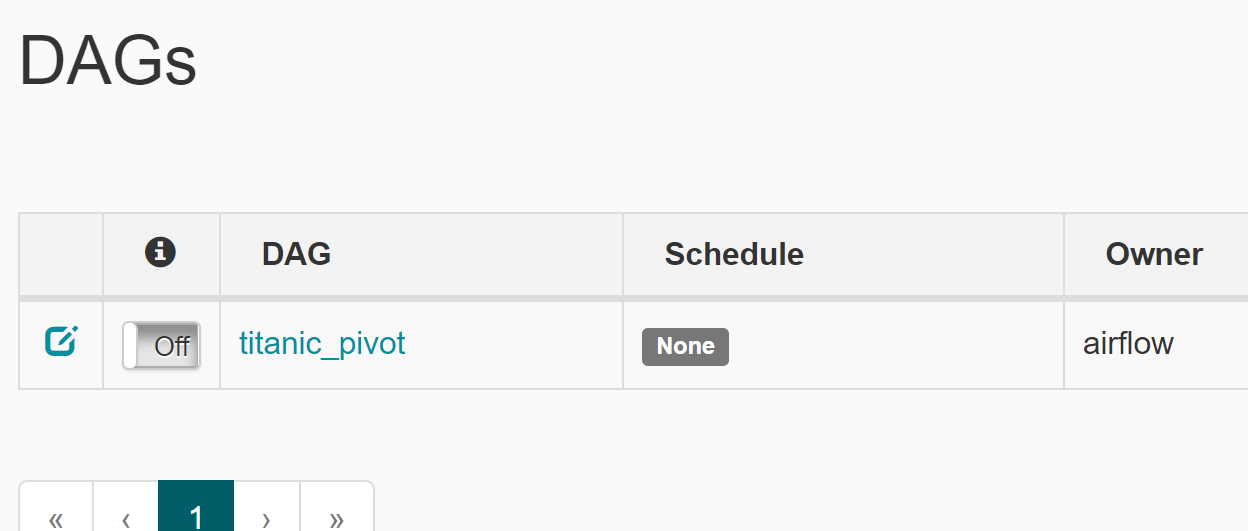
Его можно активировать, переключив с Off на On и попробовать запустить (Trigger Dag).
Заключение
Эта статья лишь небольшое введение в Apache Airflow. Я не раскрыл и 20% того, что умеет инструмент, но и такой задачи себе не ставил. Лучшим способом изучить Apache Airflow является работа с ним. Пробуйте, экспериментируйте, чтобы понять подходит он под ваши задачи или нет.
Ссылка на репозиторий с примерами: https://github.com/adilkhash/apache-airflow-intro