Строим Data Lake на Amazon Web Services
С развитием мобильных устройств, дешевого и доступного мобильного Интернета, объём генерируемых данных пользователями значительно увеличился. IoT устройства уже реалии нашего времени, а не удел фантастов прошлого века. Большая часть имеющихся данных была произведена в течение последнего десятилетия, мне страшно представить что будет в следующие 10 лет.
Инфографика ниже показывает масштабы этой дата-эпидемии.
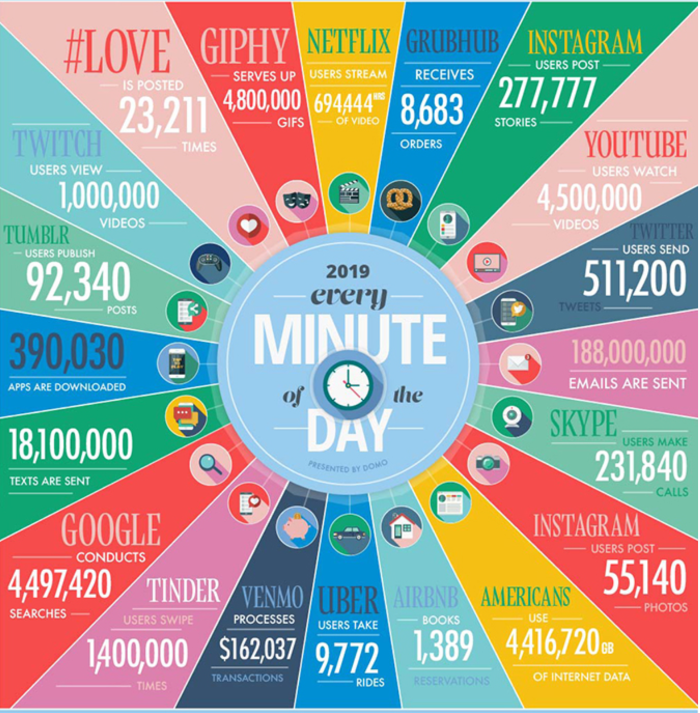
С ростом объёма данных возникают всё новые технологические вызовы по их эффективному хранению и обработке. Чтобы быть инновационными и конкурентноспособными, компаниям нужно уметь хранить, обрабатывать и анализировать нескончаемый поток информации о своих клиентах. Как это сделать?
Озеро данных / Data Lake
Этот термин стал популярен относительно недавно. Суть подхода с организацией озера данных заключается в том, что все данные с разных источников "стекаются" в одно центральное хранилище, будто множество рек впадает в одно большое озеро. Принято считать, что данные туда попадают в своём первозданном виде (сырыми), поэтому нет необходимо заранее заготавливать структурированные таблицы и очищать данные перед укладкой как это принято в традиционных DWH-системах. То есть в результате мы имеем большое хранилище с файлами разных форматов: JSON, CSV, Parquet, Avro и других.
В 2006 году мир увидел Hadoop. Революционную технологию, которая изменила способ хранения и обработки данных, которые ранее не помещались на одном компьютере. Миллионы компаний по всему миру получили возможность хранить и анализировать терабайты данных. Hadoop представляет из себя набор компонентов для хранения и анализа данных на кластере из сотен и даже тысяч компьютеров. В основе всего лежит распределенная файловая система HDFS (Hadoop File System). Представьте себе огромную файловую систему, которая размазана на тысячи компьютеров, а вы работаете с ней будто это 1 физический диск на вашем компьютере. Позже умные головы посчитали, что желательно бы научиться извлекать пользу из этих данных минимальным количеством усилий. Бесспорным лидером в этой big data гонке был SQL. Сказано - сделано. Так появился проект Apache Hive, представляющий из себя ряд компонентов, включая СУБД поверх Hadoop и SQL-подобный движок. Теперь в руках Big Data сообщества появилась возможность выполнять SQL запросы, например, на обычных csv файлах 😎
Всё бы ничего, но Hadoop комплексная система (со своими нюансами), которую необходимо установить, правильно настроить и в дальнейшем сопровождать. Не все готовы к такому.
За последние пару тройку лет сильно развились облачные системы от ведущих IT гигантов:
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
Также есть Yandex Cloud, IBM Cloud, DigitalOcean, Alibaba Cloud, но их рыночная доля значительно меньше остальных. Бесспорным лидером в облачной гонке является Amazon. Количество управляемых сервисов стремительно растёт. На момент написания статьи у AWS есть 212 доступных сервиса.
Data Lake в AWS
Реализация Data Lake средствами облачных систем имеет ряд заметных преимуществ:
- скорость разработки и получения ценности от данных (весомый плюс)
- отпадает необходимость сопровождения систем, за вас это делает облачный провайдер
- надёжность и безопасность данных (тут необходимо разбираться в настройках конкретного провайдера)
- стандарты безопасности (зачастую облачные провайдеры соответствуют различным стандартам типа PCI DSS и т.д.)
Из минусов:
- Дороговизна (спорный момент, учитывая стоимость in-house специалистов и оборудование)
- Законодательные ограничения (например, ограничения на хранение персональных данных)
- Vendor Lock или попросту брак с облачным провайдером, когда развод может стоить очень дорого 😁
Конкретно в этой статье пойдёт речь о построении озера данных средствами AWS. Мы рассмотрим доступные сервисы для реализации задачи, создадим небольшое озеро, которое наполним данными о поездках Yellow Taxi в городе Нью-Йорк. Пример с кодом доступен в репозитории моего github аккаунта. Код представляет из себя набор luigi тасков. Если вам интересно узнать больше про этот инструмент, то рекомендую мою статью про Luigi. Также на собственной платформе я создал интерактивный курс с практическими примерами построения дата-пайпланов. Поехали!
Сервисы AWS для озера данных
Далее в статье речь пойдёт про 3 фундаментальных сервиса на основе которых будем строить озеро:
- Amazon S3
- Amazon Glue
- Amazon Athena
Предлагаю рассмотреть каждый чуточку поближе.
Amazon S3
Один из самых популярных сервисов Amazon. S3 — это распределенное хранилище объектов. Вы не ограничены размером хранилища, записывать можно сколько угодно данных. Оплата идёт за хранение и операции с объектами. Над всем этим также накручены уровни доступа и шифрование. Если проводить параллель между компонентами Hadoop, то Amazon S3 это HDFS.
Amazon Glue
Amazon Glue — набор компонентов для задач типа ETL — Extract, Transform, Load. Основными компонентами Glue являются:
- хранилище метаданных (Data Catalog)
- движок ETL, генерирующий код на Python и Scala для запуска задач
- планировщик задач
В экосистеме Hadoop, Amazon Glue частично выполняет функции Apache Hive. Например, Amazon Glue Data Catalog это аналог Hive Metastore.
Amazon Athena
Amazon Athena это SQL движок на основе Apache Presto. Он умеет работать со многими форматами файлов, включая Apache Parquet, Apache Avro, ORC, CSV, JSON. Оплата со стороны Amazon идёт только за объём прочитанных данных. На момент написания статьи это $5 за 1 Тбайт данных. Согласитесь, что звучит неплохо? Такая ценовая модель вынуждает разработчиков и дата инженеров эффективно работать с данными.
О форматах
Раз речь зашла об эффективной работе с данными, отдельно стоит проговорить про различные форматы хранения. Во-первых, цена за сервис Amazon S3 напрямую зависит от объёма хранимых данных. Непозволительной роскошью будет хранить текстовые данные в их первозданном виде, их необходимо сжать. Во-вторых, цена за Amazon Athena прямопропорциональна объёму прочитанных данных. И даже тот факт, что Athena умело справляется с распаковкой тех же gzip файлов, не уменьшает объём читаемой из архива информации. Например, если вы храните csv-файл размером в 1 Гб на S3 в сжатом виде, то после распаковки файла Amazon Athena всё равно потребуется прочитать всё тот же гигабайт для выполнения аналитического запроса. Как быть? Умные головы всё уже придумали за нас. С развитием больших данных появились эффективные способы хранения и чтения данных. Одним из таких форматов является Apache Parquet.
Apache Parquet — это бинарный формат колоночного хранения данных в сжатом виде (есть ряд поддерживаемых алгоритмов сжатия, включая lzo, gzip, snappy и т.д.). Идеально подходит для представления табличных данных. Parquet-файл можно представить в виде базы данных с одной таблицей. Преимущество этого формата в эффективной компрессии файла за счёт колоночного хранения (строка по сути содержит все данные одной конкретной колонки), а также в эффективном чтении. В аналитических запросах редко присутствуют выборки всех колонок сразу, обычно читают лишь небольшое количество. Если не вдаваться в детали реализации Parquet, а попробовать объяснить представление данных внутри максимально просто, то Parquet выглядит как небольшая файловая система, где значения каждой колонки лежат в отдельных файлах, а также присутствует дополнительный файл с метаданными, где хранится информация о типах колонок и их расположении. То есть чтобы получить значения определенных колонок нужно прочитать только файлы, содержащие данные этих колонок. Надеюсь у меня получилось внятно объяснить. Подробную информацию можно найти на официальной странице Apache Parquet.
Как вы уже наверное догадались, данные в Amazon S3 я собираюсь хранить именно в формате Apache Parquet потому что:
- Файлы сжаты, поэтому хранение данных обходится дешевле
- Выборка данных из какой-либо колонки не приводит к чтению файла целиком (запросы к Amazon Athena становятся дешевле)
Также Athena поддерживает партицирование данных по какой-либо колонке/колонкам. Достаточно в S3 уложить данные в нужной структуре и при создании таблиц в Glue указать колонку по которой идёт партицирование данных.
Что даёт партицирование данных:
- Сокращение GET запросов к S3 → уменьшение стоимости
- Скорость выполнения запросов увеличивается
- Уменьшается объём читаемых данных в Amazon Athena
Создание Data Lake
Чтобы создать Data Lake необходимо:
- Создать S3 бакет
- Загрузить данные в S3 бакет, используя мой Luigi скрипт
- Настроить таблицы в Glue Data Catalog
- Проверить, что SQL в Athena отрабатывают так как нужно
Создаём S3 бакет
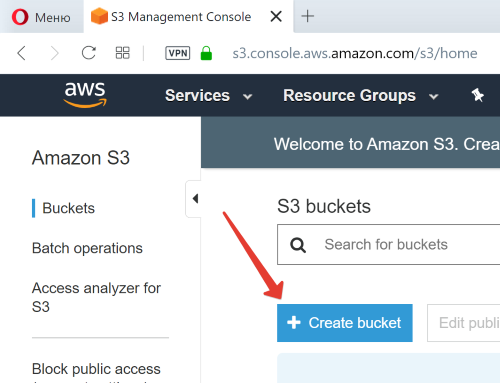
Заходите в свой AWS аккаунт и выбирайте сервис Amazon S3.
Нам необходимо создать новый S3 бакет в котором будут лежать все файлы. Нажимаем на Create bucket:
Amazon предложит вам задать новое имя бакету, в моём случае это aws-meetup-almaty:
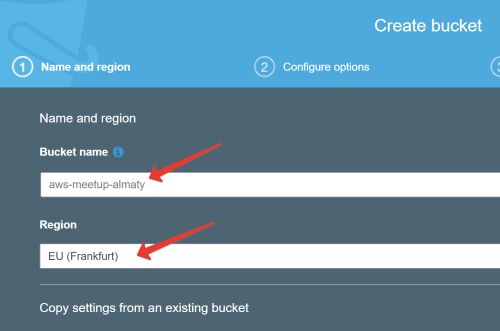
Нажимаем Next, следующие окна предлагают настроить доступ к бакету, шифрование данных и т.д. На этом этапе нам это не так важно, поэтому все настройки можно оставить в их исходном виде.
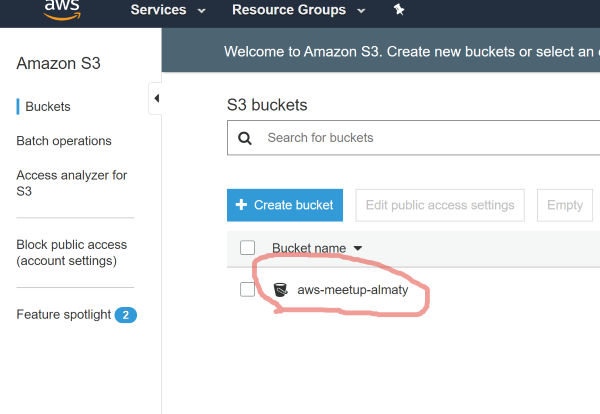
Бакет создан:
Загрузка данных на S3
Для выполнения этого шага необходимо склонировать репозиторий aws-meetup-almaty-2019-data-lake, и установить все зависимости. Для создания виртуального окружения можно воспользоваться pyenv или встроенным в python3 модулем venv. Вкратце расскажу, что делает модуль etl.
В нём 3 Luigi таска:
DownloadDatasetTask— загружает данные о поездках Yellow Taxi за март 2019 года, результатом являетсяcsvфайл.ConvertToParquetTask— преобразует загруженныйcsvфайл в Parquet предварительно отфильтровав все поездки, случившиеся не в марте 2019 года.UploadToS3Task— партицирует Parquet файл по колонкеpickup_date, полученный в результате выполнения предыдущего, и загружает данные на S3 в бакетaws-meetup-almaty. У вас будет другое название бакета, поэтому нужно будет предварительно изменить.
Запустить скрипт можно следующей командой:
python -m luigi --module etl UploadToS3Task --local-scheduler
После успешного выполнения скрипта в бакете должна появиться директория:
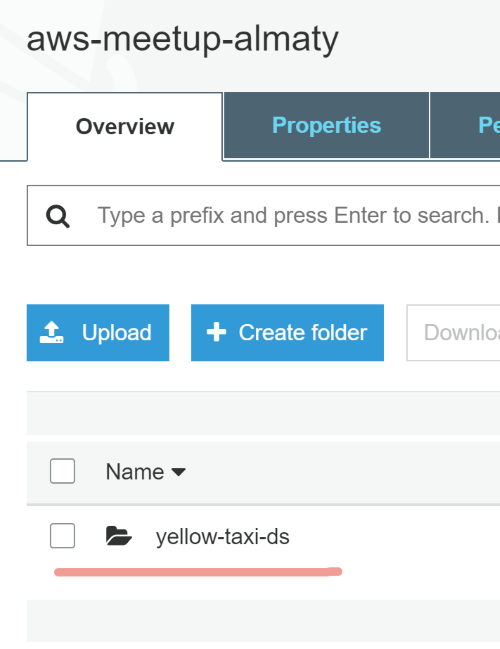
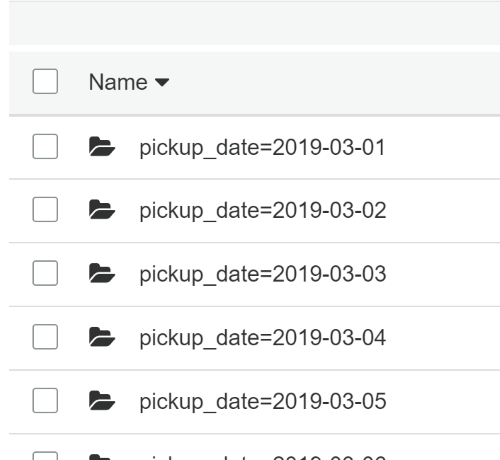
А внутри неё партицированные данные по колонке pickup_date:
Настройка AWS Glue Data Catalog
Переходим в сервис Amazon Glue. Для начала необходимо создать базу данных:
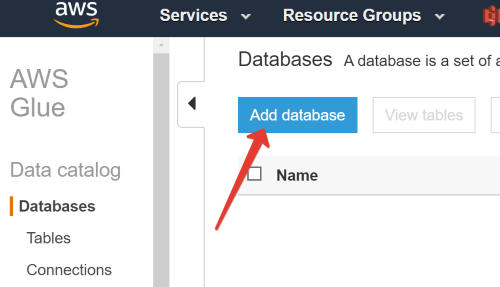
Я её обозвал aws_meetup. После успешного создания переходим в Tables. Создадим таблицу под данные на S3.
Есть 2 способа создания таблицы:
- Вручную, указав все поля и их тип
- Через Glue Crawler, который сам всё сделает за нас.
Я предпочитаю Glue Crawler, т.к. он всю работу делает за нас. Но запуск Crawler платная услуга, хоть и стоит копейки. Подробнее о цене можно узнать тут. Более того, если пополнение будет периодическим, то crawler можно настроить на запуск по расписанию.
Выбираем добавление таблицы, используя crawler. В окне создания необходимо задать имя и источник из которого забирать файлы, а также выбрать IAM роль из под которой будет происходить операция. После успешного создания переходите в Crawlers, и запускайте паучка.
После успешного выполнения задачи в разделе Tables должна появиться новая таблица:

Всё готово.
Теперь можно открыть сервис Amazon Athena, выбрать новую базу данных и начинать писать запросы через интерактивный шелл.
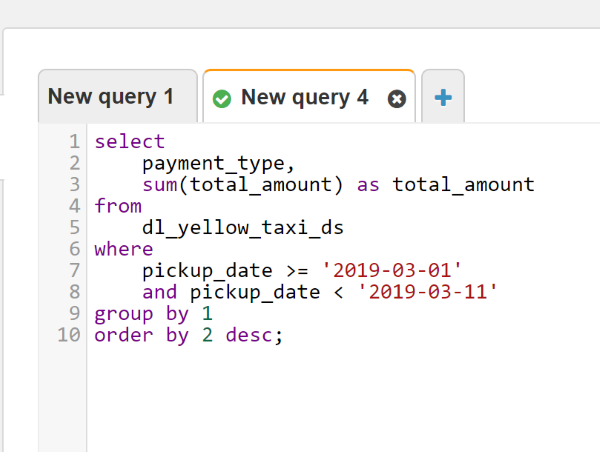
Также, используя библиотеку boto3, можно формировать запросы через код. В репозитории лежит пример функции, выполняющей запрос в Athena.
Вывод
Моей целью было максимально просто и быстро показать как можно создавать свои data lakes, используя сервисы Amazon. Не так давно в экосистеме AWS появился новый сервис под названием AWS Lake Formation, который автоматизирует рутинную работу по перегону данных из различных источников. На сервис определенно стоит обратить своё внимание.
Надеюсь, что у меня получилось продемонстрировать насколько легко и быстро можно поднять масштабируемый data lake средствами Amazon Web Services.