 English
EnglishОконные функции SQL
Оконные функции SQL это, пожалуй, самая мистическая часть SQL для многих веб-разработчиков. Нередко встретишь и тех, кто и вовсе никогда о них не слышал. Да что греха таить, я сам продолжительное время не знал об их существовании, решая задачи далеко не самым оптимальным способом.
Оконные функции это функции применяемые к набору строк так или иначе связанных с текущей строкой. Наверняка всем известны классические агрегатные функции вроде AVG, SUM, COUNT, используемые при группировке данных. В результате группировки количество строк уменьшается, оконные функции напротив никак не влияют на количество строк в результате их применения, оно остаётся прежним.
Привычные нам агрегатные функции также могут быть использованы в качестве оконных функций, нужно лишь добавить выражение определения "окна". Область применения оконных функций чаще всего связана с аналитическими запросами, анализом данных.
Из чего состоит оконная функция
<название функции>(<выражение>) OVER (
<окно>
<сортировка>
<границы окна>
)
Лучше всего понять как работают оконные функции на практике. Представим, что у нас есть таблица с зарплатами сотрудников по департаментам. Вот как она выглядит:
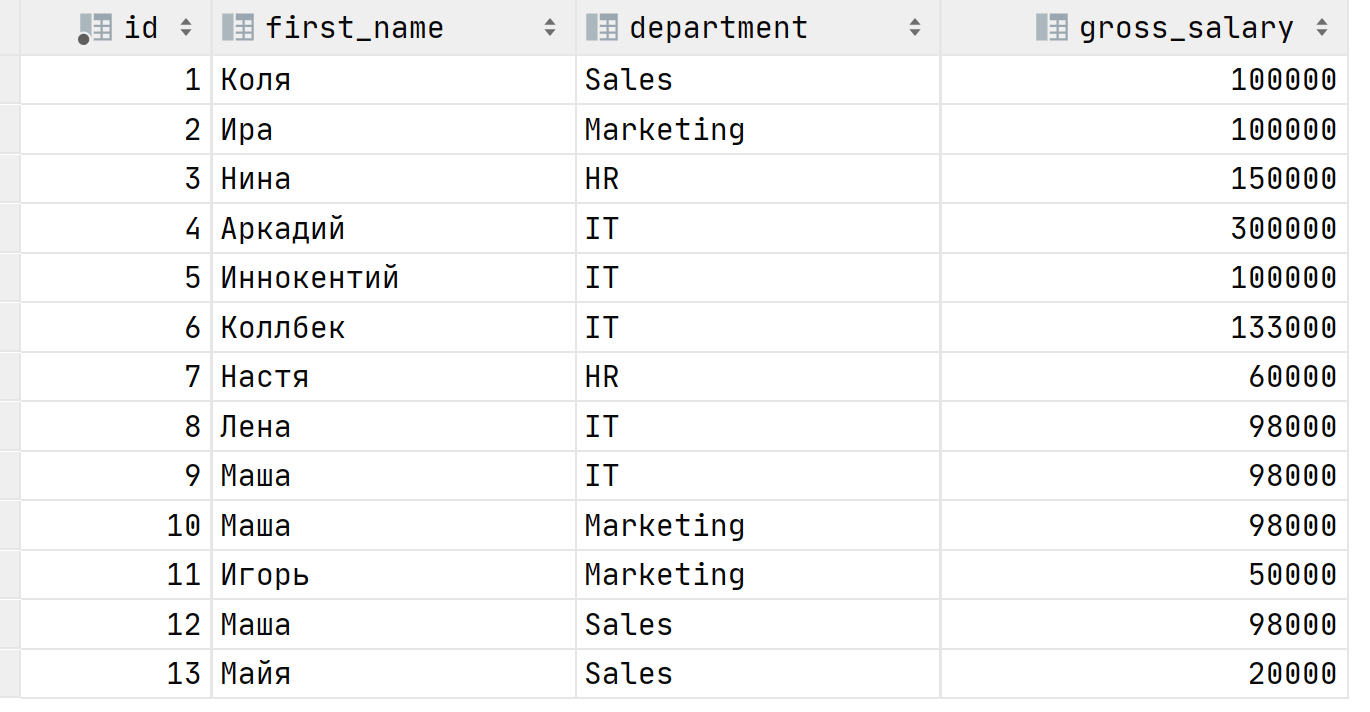
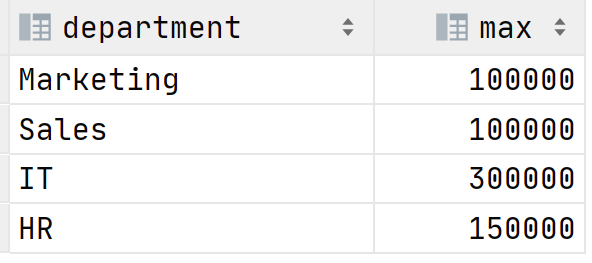
В связи с пандемией коронавируса необходимо оптимизировать расходы путем сокращения сотрудников или понижения их зарплат. Ваш вечнонедовольный директор приходит к вам с просьбой выяснить кто получает больше всего в каждом департаменте. Как поступить? Можно использовать агрегатные функции, в нашем случае MAX, чтобы выяснить максимальную зарплату в каждом отделе:
SELECT
department,
MAX(gross_salary) as max_salary
FROM Salary
GROUP BY 1;
Результат выполнения запроса:
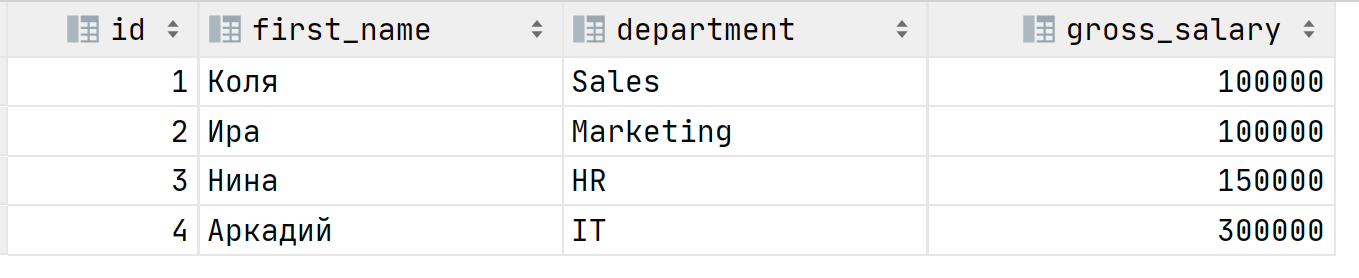
Чтобы узнать кто эти "счастливчики" на сокращение можно выделить запрос в подзапрос и объединить с исходной таблицей путём JOIN:
SELECT
id,
first_name,
department,
t.gross_salary
FROM Salary
JOIN (
SELECT
department,
MAX(gross_salary) as gross_salary
FROM Salary
GROUP BY 1
) t USING(gross_salary, department);
В результате:
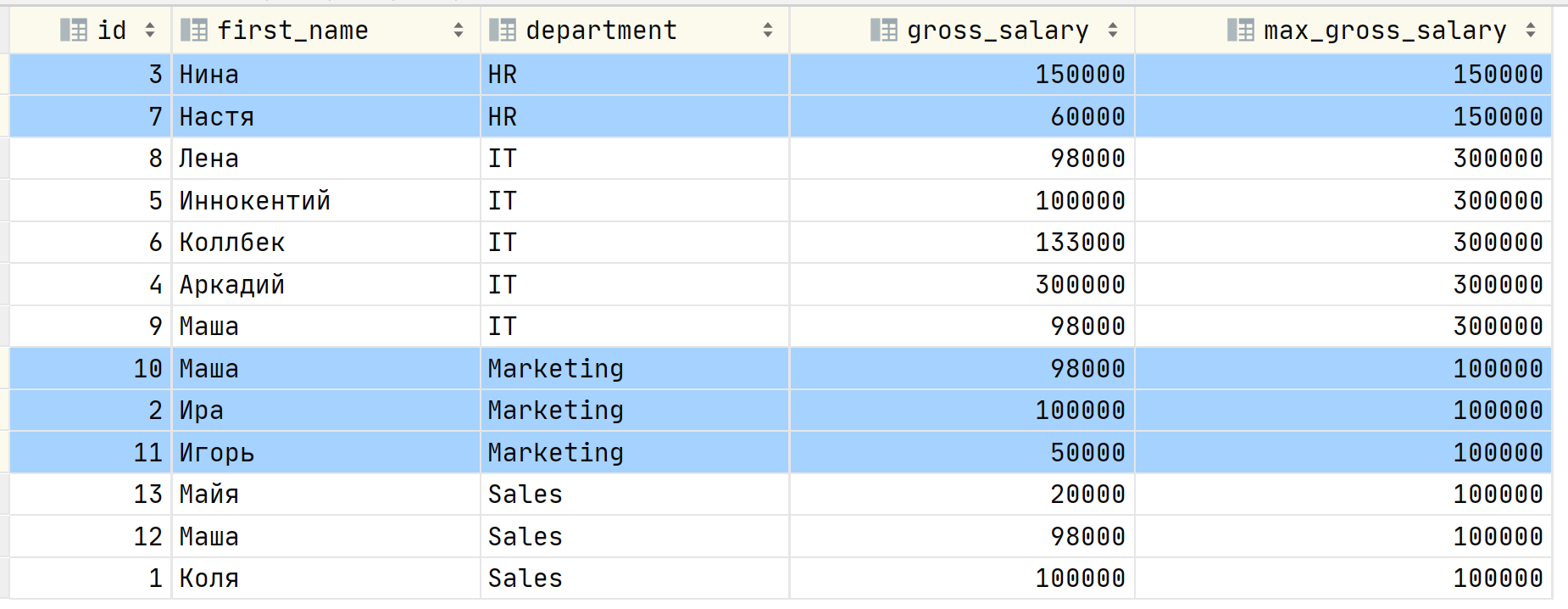
Но тут вы вспоминаете, что эту же задачу можно решить, используя оконные функции, которые вы проходили на одной из лекций по SQL в универе в бородатом году. Как? Используя всё ту же агрегатную функцию MAX, задав "окно". Окном в нашем случае будут сотрудники одного департамента (строки с одинаковым значением в колонке department).
SELECT
id,
first_name,
department,
gross_salary,
MAX(gross_salary) OVER (PARTITION BY department) as max_gross_salary
FROM Salary;
Окно задаётся через выражение OVER (PARTITION BY <колонки>), т.е. строки мы как бы группируем по признаку в указанных колонках, конкретно в этом случае по признаку принадлежности к департаменту в компании. Результат запроса:
Чтобы отфильтровать потенциальных кандидатов на сокращение можно выделить запрос в подзапрос:
SELECT *
FROM (
SELECT id,
first_name,
department,
gross_salary,
MAX(gross_salary) OVER (PARTITION BY department) as max_gross_salary
FROM Salary
) t
WHERE max_gross_salary = gross_salary
ORDER BY id;
Результат будет точно таким же как и при объединении. Итак, с чувством собственного величия, ощущая себя цифровым палачом вы отправляете результат своему начальнику. Он смотрит на вывод и говорит, что у Аркадия из IT отдела зарплата 300 000, но другой сотрудник в этом же отделе может получать 295 000, разница между ними будет несущественна. Покажи мне пропорцию зарплат в отделе относительно суммы всех зарплат в этом отделе, а также относительно всего фонда оплаты труда!
Как решать? Можно пойти тем же путём, используя подзапросы:
WITH gross_by_departments AS (
SELECT
department,
SUM(gross_salary) as dep_gross_salary
FROM Salary
GROUP BY 1
)
SELECT
id,
first_name,
department,
gross_salary,
ROUND(CAST(gross_salary AS numeric(9, 2)) / dep_gross_salary * 100, 2) as dep_ratio,
ROUND(CAST(gross_salary AS numeric(9, 2)) / (SELECT SUM(gross_salary) FROM Salary) * 100, 2) as total_ratio
FROM Salary
JOIN gross_by_departments USING(department)
ORDER BY department, dep_ratio DESC
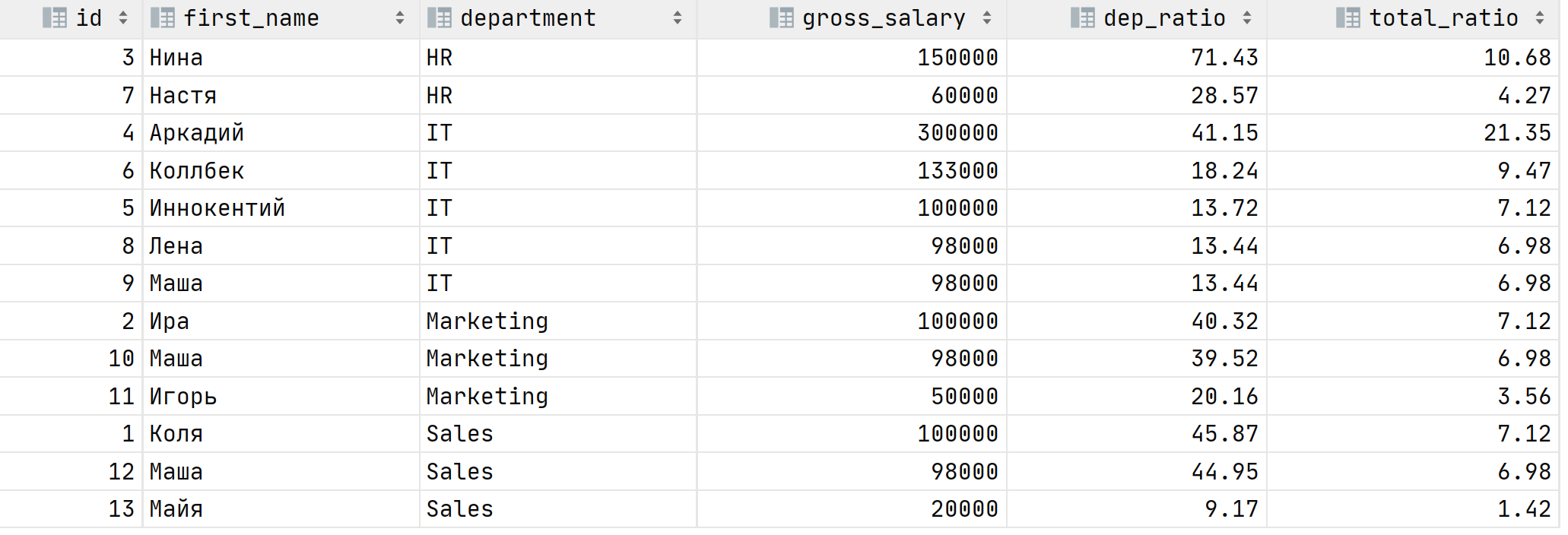
На этой таблице видно, что зарплата Нины это 71% расходов на HR отдел, но лишь 10.5% от всего ФОТ, а вот Аркадий выделился, конечно. Его зарплата это 41% от зарплаты всего IT отдела и 21% от всего ФОТ! Идеальный кандидат на сокращение 😈 Но не кажется ли вам, что SQL запрос малость сложный? Давайте попробуем его написать через оконные функции:
SELECT
id,
first_name,
department,
gross_salary,
ROUND(CAST(gross_salary AS numeric(9,2)) / SUM(gross_salary) OVER (PARTITION BY department) * 100, 2) as dep_ratio,
ROUND(CAST(gross_salary AS numeric(9,2)) / SUM(gross_salary) OVER () * 100, 2) as total_ratio
FROM Salary
ORDER BY department, dep_ratio DESC;
Кратко, понятно, содержательно! Выражение OVER() означает, что окном для применения функции являются все строки, т.е. SUM(gross_salary) OVER(), означает что сумма будет посчитана по всем зарплатам независимо от департамента в котором работает сотрудник.
Что дальше
В примере выше мы использовали исключительно агрегатные функции как оконные, но в стандарте SQL есть исключительно оконные функции, которые невозможно использовать как агрегатные, это значит, что их невозможно применить при обычной группировке. Вот лишь часть оконных функций, доступных в PostgreSQL:
- first_value
- last_value
- lead
- lag
- rank
- dense_rank
- row_number
Со всеми доступными оконными функциями можно ознакомиться в официальной документации PostgreSQL.
Использование оконных функций
В задаче определения самого высокооплачиваемого сотрудника мы использовали агрегатные функции MAX, SUM, давайте рассмотрим чисто оконную функцию first_value. Она возвращает первое значение согласно заданного окна, т.е. применимо к нашей задаче она должна вернуть имя сотрудника у которого самая высокая зарплата в департаменте.
SELECT
id,
first_name,
department,
gross_salary,
first_value(first_name) OVER (PARTITION BY department ORDER BY gross_salary DESC ) as highest_paid_employee
FROM Salary
last_value делает то же самое только наоборот, возвращает самую последнюю строчку. Давайте найдём с помощью неё самого низкооплачиваемого сотрудника в департаменте.
SELECT id,
first_name,
department,
gross_salary,
last_value(first_name)
OVER (PARTITION BY department ORDER BY gross_salary DESC) AS lowest_paid_employee
FROM Salary
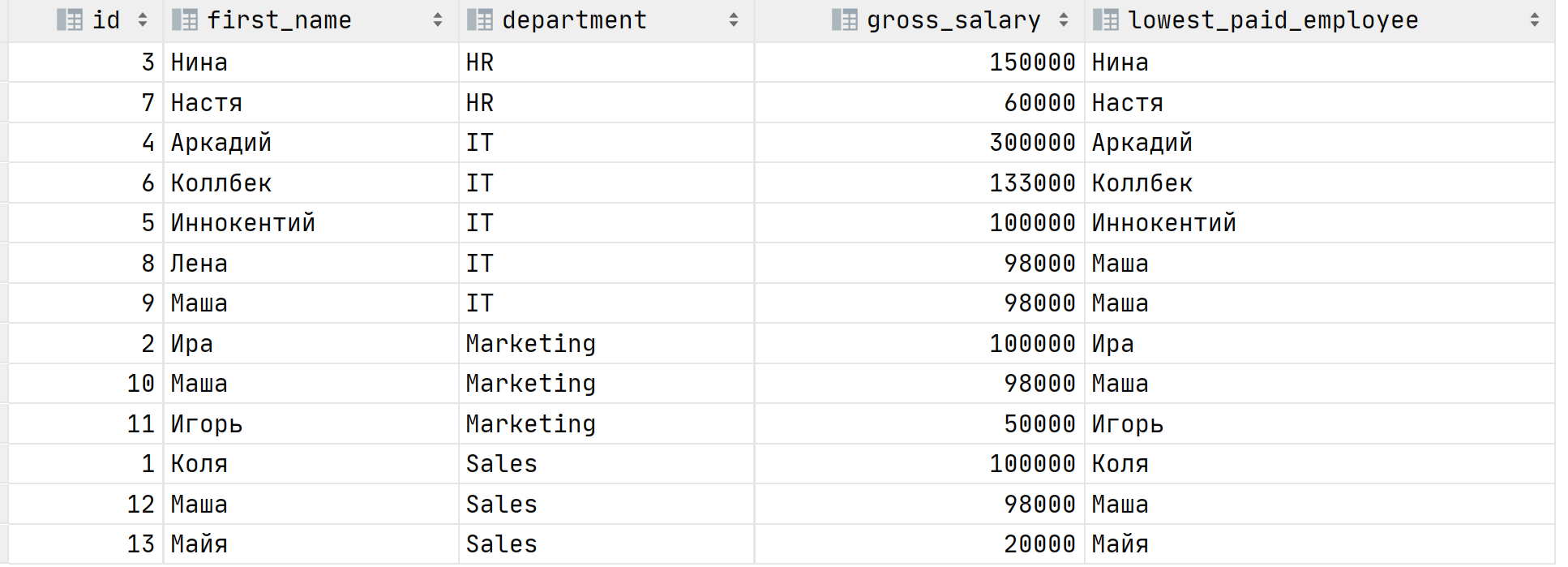
Если внимательно взглянуть на результат выполнения запроса, то можно понять, что он неверный. Почему? А потому что мы не указали диапазон/границы окна относительно текущей строки. По умолчанию, если не задано выражение ORDER BY внутри OVER, то границами окна являются все строки, если ORDER BY задан, то границей для текущей строки будут все предшествующие строки и текущая, в терминах SQL это ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. В этом можно убедиться, если внимательно взглянуть на результат выполнения крайнего запроса.
Как исправить ситуацию? Расширить границы окна. Перепишем наш запрос, указав в качестве границ все предшествующие строки в окне и все последующие. В терминах SQL это выражение ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING:
SELECT id,
first_name,
department,
gross_salary,
last_value(first_name)
OVER (
PARTITION BY department
ORDER BY gross_salary DESC
ROWS BETWEEN
UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
) as lowest_paid_employee
FROM Salary
Визуально это выглядит примерно как на картинке ниже.
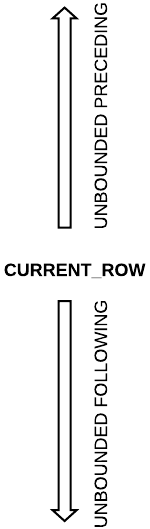
Границы можно определять рядом выражений:
- N PRECEDING, N строк до текущей строки
- CURRENT ROW, текущая строка
- UNBOUNDED PRECEDING, все строки, предшествующие текущей
- UNBOUNDED FOLLOWING, все последующие строки
- N FOLLOWING, N строк после текущей строки