 Русский
РусскийIntroduction to Window Functions in SQL
It is interesting that many people working with data have no clue about window functions in SQL. During a long period of time instead of using window functions, I preferred coding in Python and pandas. Today I would like to introduce you to the concept of "window" and how it is related to data extraction from a SQL database.
Window functions are applied to a subset/window of rows related to one another. In comparison to GROUP BY operation, window functions do not decrease the number of rows. Aggregate functions like AVG, SUM, COUNT could be used as window functions as well. Usually, window functions are used to do analytical tasks. The following examples of queries will be performed on the PostgreSQL database.
Syntax
<function>(<expression>) OVER (
<window>
<sorting>
<window range> -- optional
)Looks creepy 😲 We need more practice. Let's assume that we have a salary table:
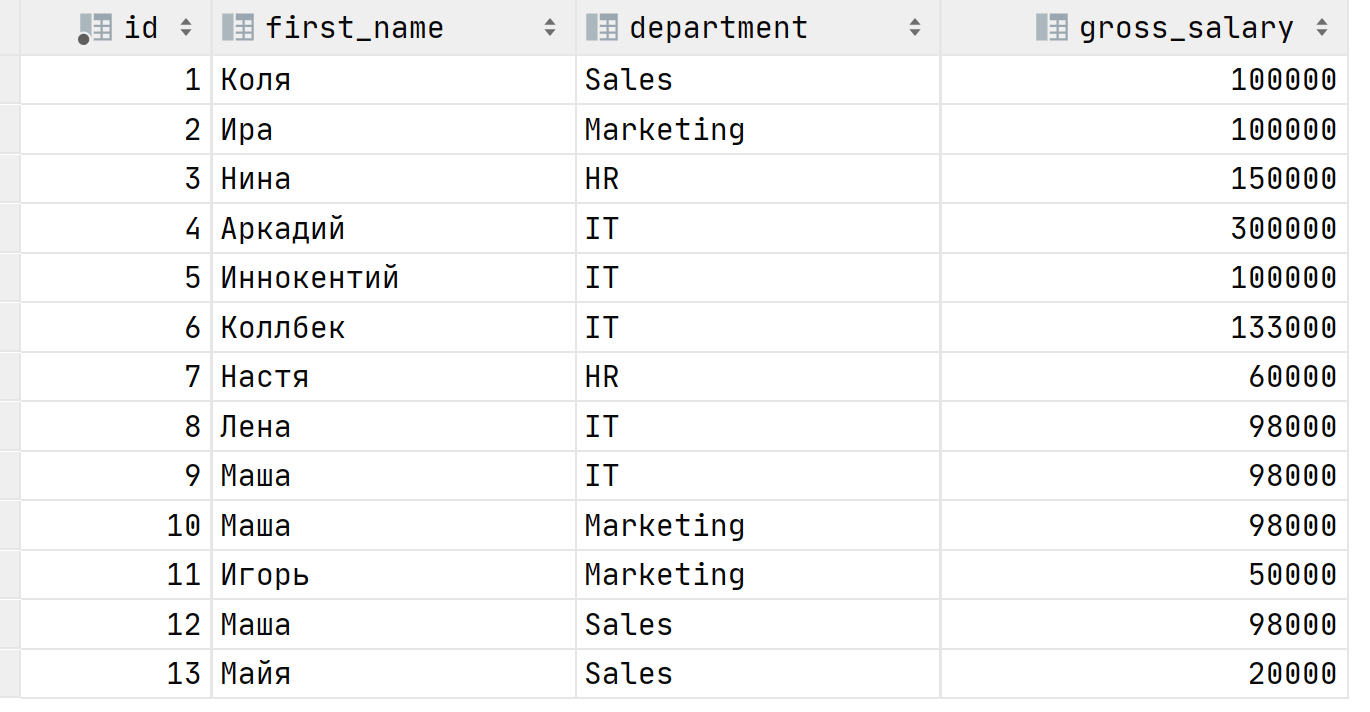
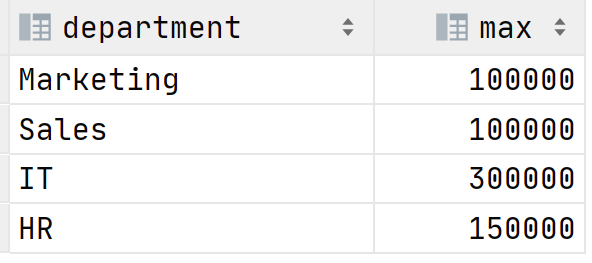
One day your boss approaches you, he wants to know who is the highest-paid employee by the department. We can use the MAX function to select the highest salary for each department.
SELECT
department,
MAX(gross_salary) as max_salary
FROM Salary
GROUP BY 1;
The result is:
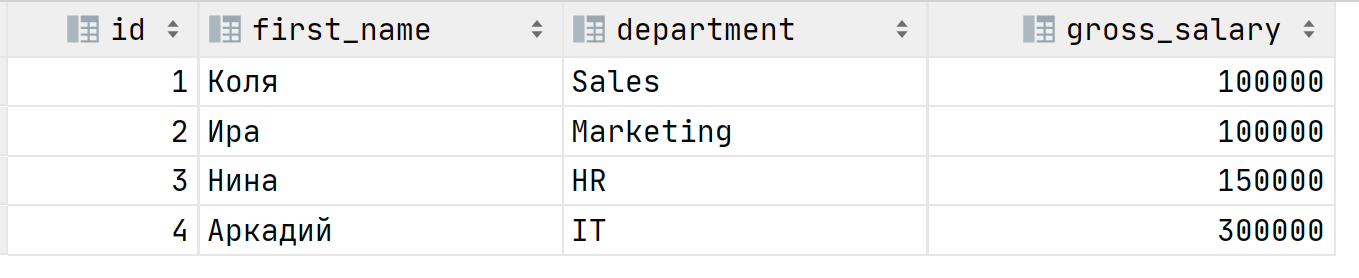
In order to select the person with the highest salary by department, we can use a subquery and JOIN:
SELECT
id,
first_name,
department,
t.gross_salary
FROM Salary
JOIN (
SELECT
department,
MAX(gross_salary) as gross_salary
FROM Salary
GROUP BY 1
) t USING(gross_salary, department);
The result is:
But the query looks verbose and dirty, maybe we can do the same with window functions? Sure. All you need to do is to set up a window for MAX aggregate function:
SELECT
id,
first_name,
department,
gross_salary,
MAX(gross_salary) OVER (PARTITION BY department) as max_gross_salary
FROM Salary;
The column department is a window. It means that employees from the same department is a subset or window of related rows. The result of the query:
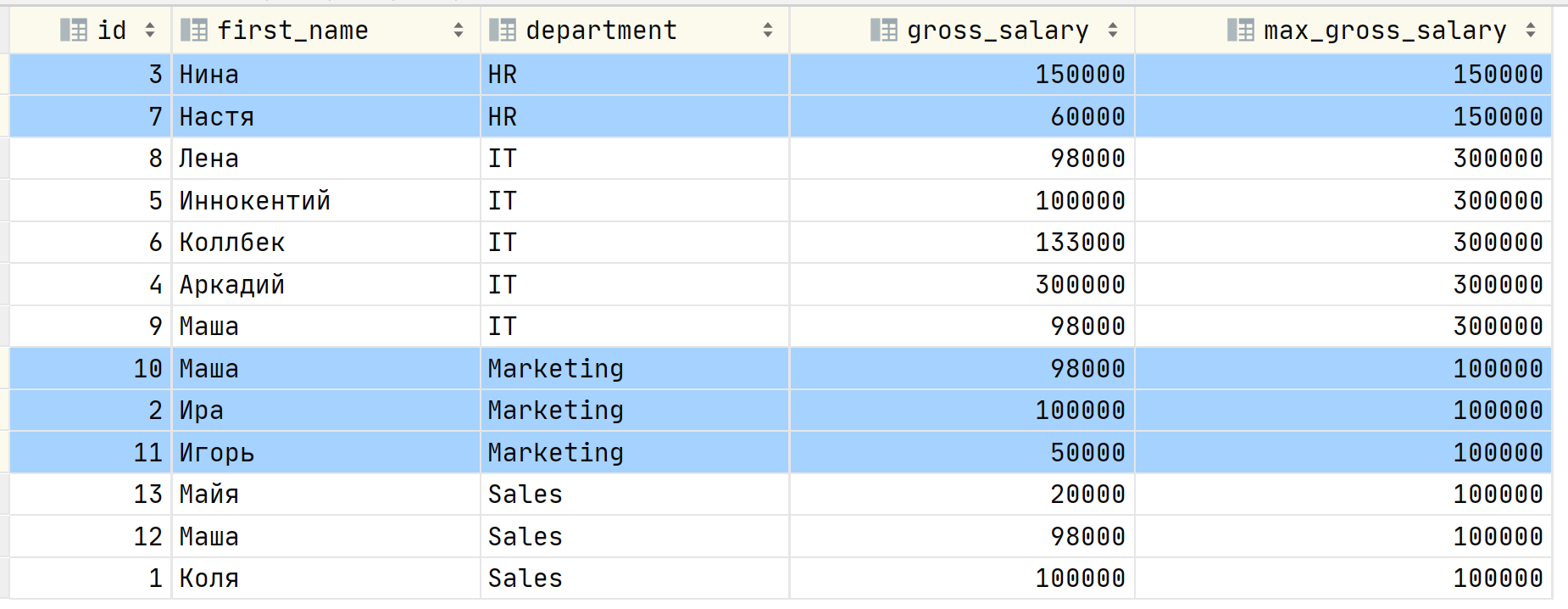
As you can see we have the new column called max_gross_salary which shows the highest salary in each department. In order to retrieve the list of most paid employees we do the following:
SELECT *
FROM (
SELECT id,
first_name,
department,
gross_salary,
MAX(gross_salary) OVER (PARTITION BY department) as max_gross_salary
FROM Salary
) t
WHERE max_gross_salary = gross_salary
ORDER BY id;
Now your boss asks you to prepare the report which shows the ratio of salaries by department and by the total wage fund because some departments have relatively low-income employees in comparison with other departments. You can solve it using subqueries:
WITH gross_by_departments AS (
SELECT
department,
SUM(gross_salary) as dep_gross_salary
FROM Salary
GROUP BY 1
)
SELECT
id,
first_name,
department,
gross_salary,
ROUND(CAST(gross_salary AS numeric(9, 2)) / dep_gross_salary * 100, 2) as dep_ratio,
ROUND(CAST(gross_salary AS numeric(9, 2)) / (SELECT SUM(gross_salary) FROM Salary) * 100, 2) as total_ratio
FROM Salary
JOIN gross_by_departments USING(department)
ORDER BY department, dep_ratio DESC
The result is:
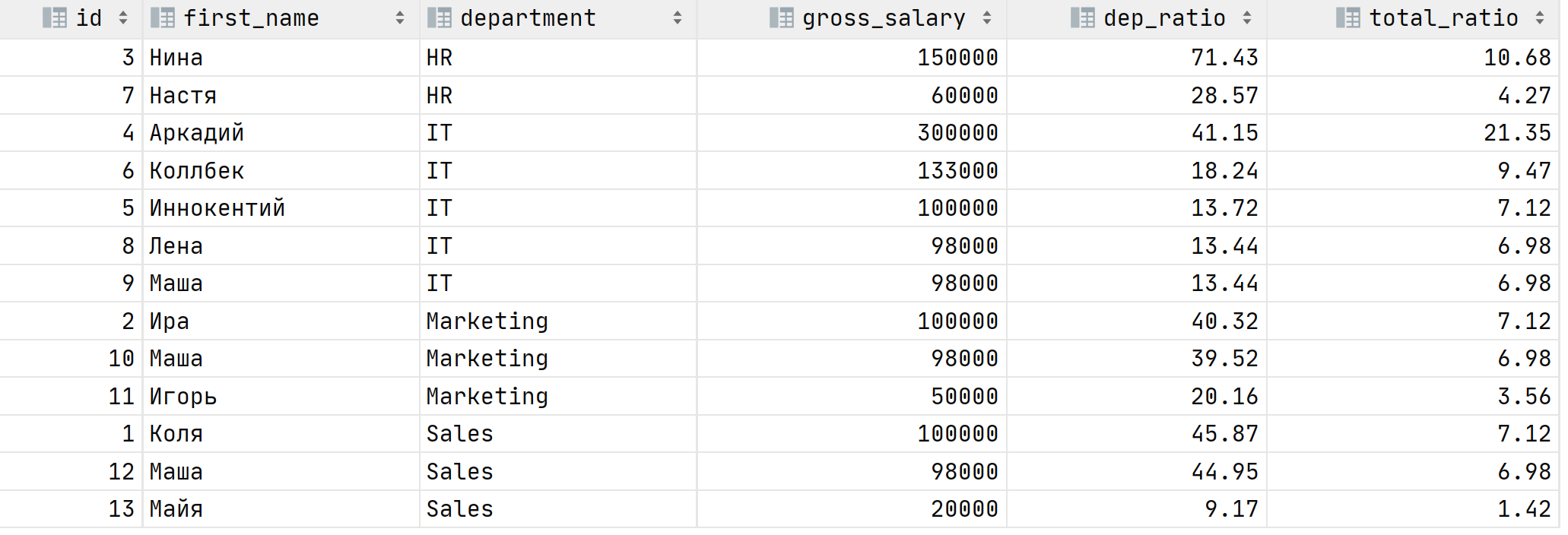
As you can see Нина earns 71.4% out of HR department, but it is only 10.7% out of the total wage fund. Аркадий on the other hand has 21.4% out of total wage fund and 41% out of IT department. Can we refactor the query to make it smaller and more readable? Yes! Window functions!
SELECT
id,
first_name,
department,
gross_salary,
ROUND(CAST(gross_salary AS numeric(9,2)) / SUM(gross_salary) OVER (PARTITION BY department) * 100, 2) as dep_ratio,
ROUND(CAST(gross_salary AS numeric(9,2)) / SUM(gross_salary) OVER () * 100, 2) as total_ratio
FROM Salary
ORDER BY department, dep_ratio DESC;
The expression OVER() means that the "window" is all rows.
Window functions only
We used the aggregate functions MAX & SUM as window functions above. But SQL standard consists of functions that cannot be used as aggregates hence no way to apply them during grouping. Here is the list of them:
- first_value
- last_value
- lead
- lag
- rank
- dense_rank
- row_number
A comprehensive list of all window functions supported in PostgreSQL you can find here.
Using window functions
Let's use the first_value function in order to solve the very first problem where we were asked to get the name of the highest-paid employee by each department. The function returns the very first values according to the provided window.
SELECT
id,
first_name,
department,
gross_salary,
first_value(first_name) OVER (PARTITION BY department ORDER BY gross_salary DESC ) as highest_paid_employee
FROM Salary
We are sorting the rows in our window by salary in descending order, which means that the very first row will be a person with the highest salary.
Now let's use last_value. It does the opposite of what first_value does.
SELECT id,
first_name,
department,
gross_salary,
last_value(first_name)
OVER (PARTITION BY department ORDER BY gross_salary DESC) AS lowest_paid_employee
FROM Salary
The result is:
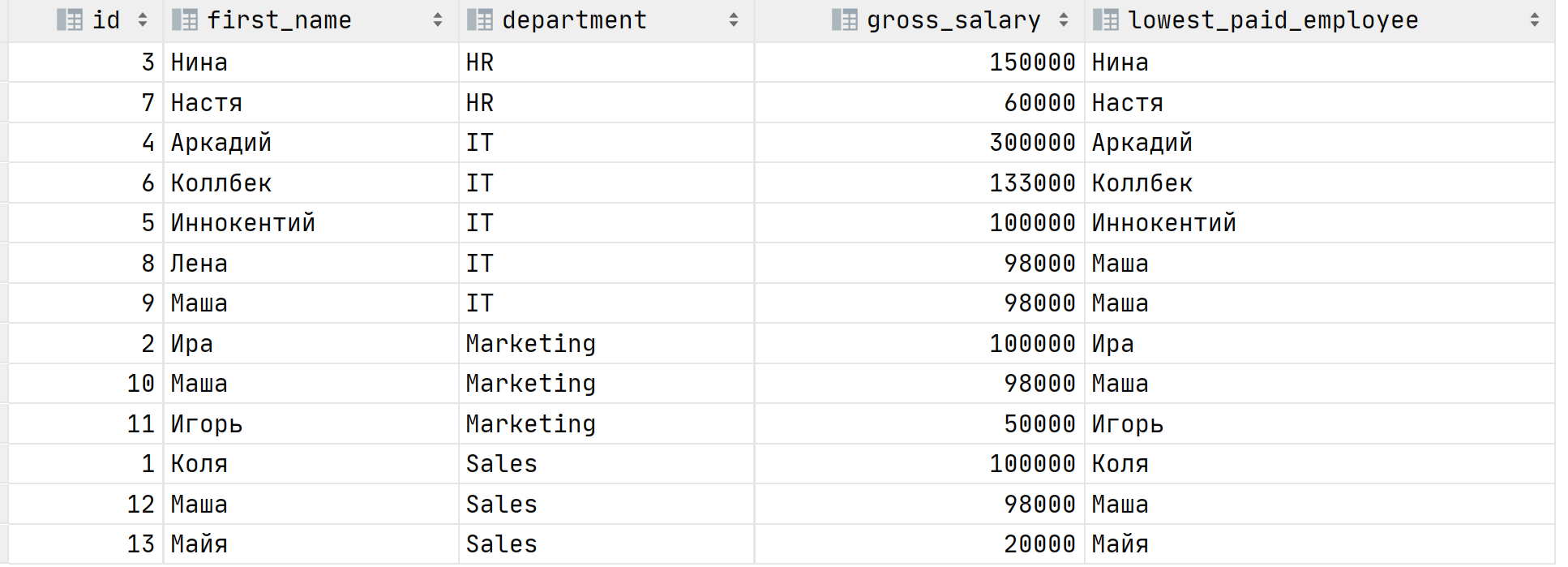
If you look at the table you will see that the result is wrong. Why? Because of window ranges. By default, if you provide the ORDER BY clause the window range is all preceding rows and current row, in SQL terms it is ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. It means that the last_value for a particular column in a particular row is a column in the same row. In order to fix this problem, we need to change the range to ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING:
SELECT id,
first_name,
department,
gross_salary,
last_value(first_name)
OVER (
PARTITION BY department
ORDER BY gross_salary DESC
ROWS BETWEEN
UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
) as lowest_paid_employee
FROM Salary
This is how it looks visually:
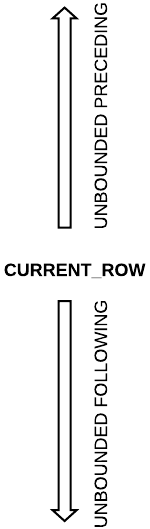
The possible values:
- N PRECEDING, N number of rows until current row
- CURRENT ROW
- UNBOUNDED PRECEDING
- UNBOUNDED FOLLOWING
- N FOLLOWING**, N number of rows following the current row